
七年前我在VDMA的一个峰会演讲时谈到智能物流,为了佐证我们国家的总体物流效率不高,用到了如下的一张图。
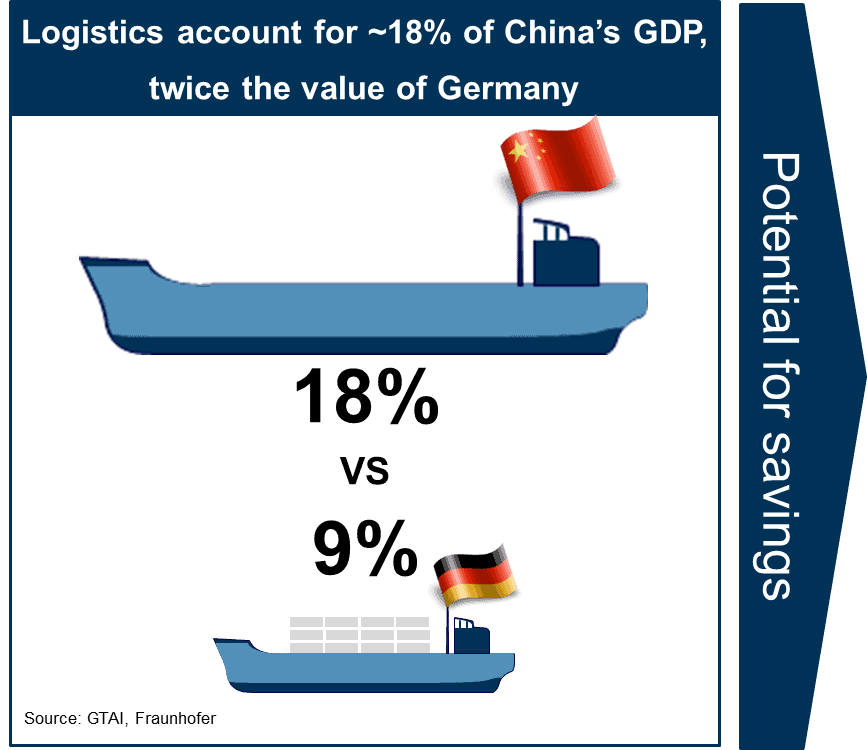
今年当我再翻到这页PPT时,发现自己掉进了思维陷阱。碰巧最近又翻到了世界银行的一篇文章Logistics Costs and Economic Development,开头便是下面这张图表。
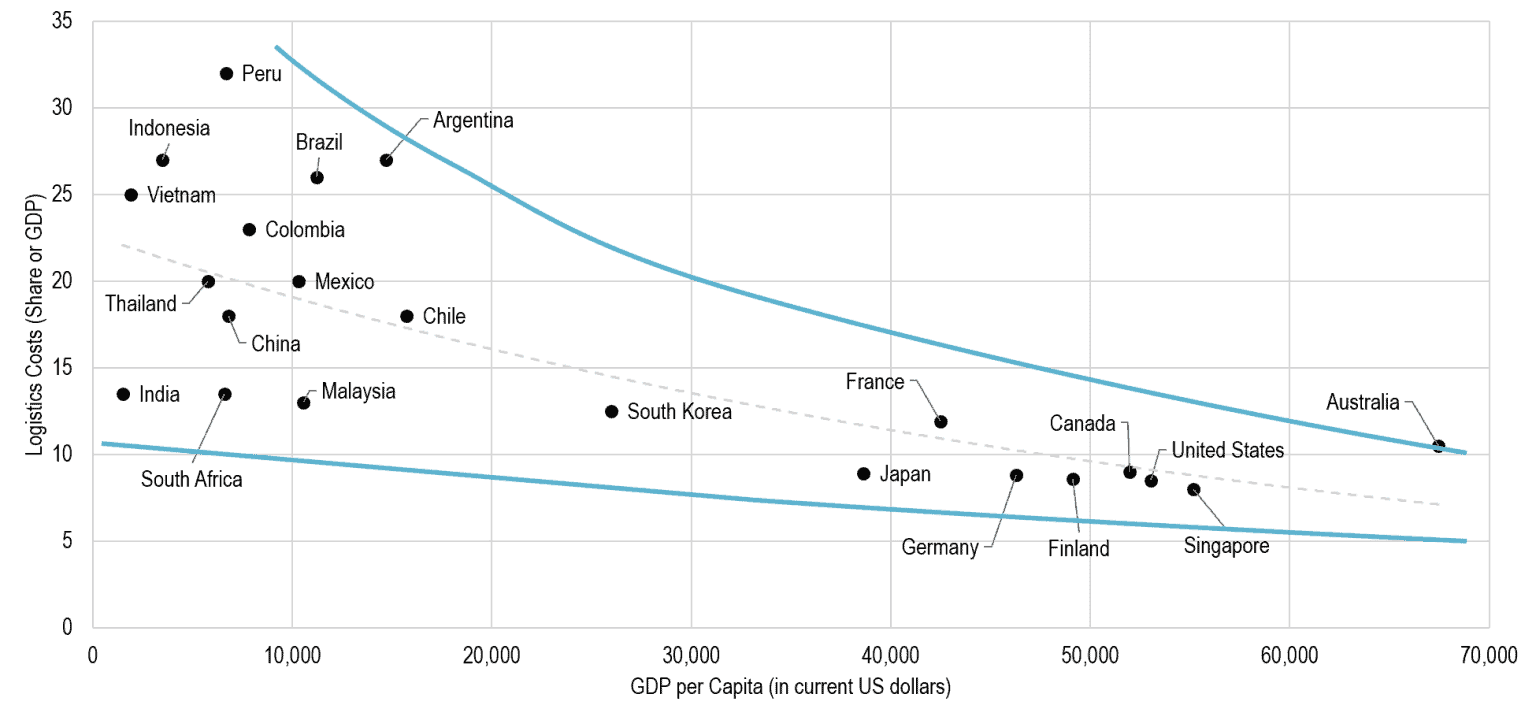
如何从数据中获得有效的信息,单看开篇的图表,你是得不到任何有价值的信息的。
世界银行的这篇文章中阐述道:
There is a relationship between the level of economic development (as measured in terms of GDP per capita), the composition of a national economy, and logistics costs. While logistics costs can amount to 25% of delivered costs in some developing economies, they can go as low as 8% in advanced economies. Many factors can influence this cost structure:
Transportation infrastructures. They influence transport costs, capacity, and reliability. Extensive transport infrastructures are linked with lower logistics costs.
Role of economic sectors. Economies relying on the primary (e.g. agriculture and mining) and secondary (manufacturing) sectors have higher logistics costs than economies relying on the tertiary (services) sector. These variations are linked with the amount of freight in circulation in relation to the total economic output.
理解下来的意思就是以服务业和虚拟经济为主的经济体,衡量整体物流成本是没意义的。而以农业来说,各国所种植的作物分布状况以及单位面积产生的经济价值不一样,带来的自然是物流费用占总成本的巨大差异。零售物流亦是如此,所以,要比较,只能拿相近的经济细分领域和地理分布来看,不然就是耍流氓。不同的物流成本结构因素对这个数值也会影响很大,你看新加坡,作为天底下最大号的一个收费站,自然物流成本占GDP要低很多。同样的,中德之间比较物流占GDP的比例,一样没有什么意义,两者制造业占GDP的比例,国家的幅员和产业集群,都完全不一样。
TED也有一个很有趣的视频,同样很好地阐述了数据分析中容易被误导的例子。
由此可见,原始数据中的不同细节经人为操纵加工进行不同的分组,便会造成数据解读的这些偏差。
这样的例子在制造业中则更为普遍,比如,管理层收到的报表中,明显看到人力成本的下降,便会认为是件好事情,然而背后却是高薪的熟练工人的减少,低薪的临时工的增多,因而带来的产品良率的下降和质量成本的增加。再比如,数据报表中设备效率在当月提升很多,但是,背后的代价却是单一产品的过度生产带来的高库存和滞销。
解决这类问题的方法其实并不能够被简单概括,但是在数字化基础设施架构的时候入手,我们可以尝试找出一些脉络,比如:
- 在运营数字化转型时尽可能地收集保留数据的一些细节
- 在数据归纳和分析时要有足够的弹性和柔性来以多种方式呈现
- 在分析数据图表时,要尽可能地考虑比对不同时间场景下的数据切片
- 不要盲目地与外部数据进行简单地对比,如果要对比,需要能够有较为详尽的数据细节
- 在管理架构上,尽可能地将业务执行者与数据操作者进行权责分离,以避免人为的数据操纵
在企业持续地进行数字化提升并产生巨量数据的同时,如何避免这些数据中的陷阱,让企业运营管理人员能够更好地基于数据与事实进行决策,而不是被误导后做出错误的判断,将会是未来企业面临的一个重要课题。

“Strategy starts with answering the question: what are we not doing anymore?”
Dr. Christoph Weiss has many years of experience in industry, including at Daimler and Festool. He has advised on many international projects – in the chemical, automotive and electrical engineering sectors – and authored the bestseller: “Doomed to Excellence”. Dr. Weiss is the CEO of Fein, which was founded 150 years ago and has an excellent reputation worldwide in the manufacturing of power tools. In the following interview, he talks about the courage to focus clearly and how this has a positive effect on the costs, complexity and success of a company.
Read more
工厂改善的良机-精益布局改善
近些年来,随着公司业务不断扩展,加上订单模式的客制化越来越多,我们的生产组织模式,尤其是生产布局方面限制了公司的发展。随着新机器数量的不断增加,机器分区显得杂乱无序;而且未来还会有更多的新产品/新工艺,这意味着对工厂的布局要求会更高。工厂布局调整迫在眉睫。 生产布局的调整和重新规划涉及精益布局概念。精益布局是精益的概念和原则在更大范围的应用。大多数时候,我们讨论精益工作时会集中在细节上,比如我如何减少这种转换时间,如何消除工作空间的浪费,如何提高产线的工作效率等。精益布局是大局观, 高空俯视的视角去考虑问题,比如你是如何排布生产设备的?我们的浪费在哪里?整个生产组织的流动性和及时性是如何实现的? 精益布局在提高物流效率以及减少劳动力方面表现尤为突出。下面以一个小型机加车间的布局为例,下面是做布局改善前后的对比图: 通过将工厂车间重新布置成“I”形布局,他们将作业员需求从15名工人减少到12名。通过重新布置机器并控制生产节拍,使其与客户节拍一致,仅使用12名工人即可操作所有流程,生产效率提高了25%。节拍的变化,使得原本过度堆积的中间库存降低了60%,释放资金达到300万人民币。由于精益布局的调整,整个生产组织实现了一个质的飞跃。 精益布局不仅可以应用于生产设备的排布,还可以结合辅助功能模块的优化,如员工在哪里更换劳保用品?哪里领用生产辅助用品?这些区域是否尽可能靠近生产区域? 精益布局和参观路径的结合,完美呈现了公司运营的现状。我们原有的车间,由于生产规模的不断扩展,机器设备的排布经常是和工艺流程不相符的。这也造成了我们在客户参观时,讲解的工艺步骤和看到的现场不匹配,经常会跳跃式的讲解或者往复式的参观。精益规划的布局,完美融合工艺和参观路径,加上信息化的支持,既能快速讲解,客户又能有很好的视觉体验。 精益布局的开展步骤: 精益布局的实施步骤包含蓝图规划和细致规划两个阶段。 蓝图规划阶段,包含了生产布局和自动化两个模块。生产布局方面重点看生产工艺的优化、价值流程图的分析与设计等,不仅只是做布局规划,同时结合了精益改善计划。在改善的基础上,寻求最优的布局。同时考虑仓库物流的策划,与新时代下的职能物流结合,既要满足物流便捷,又要满足稳定的传输和信息快速共享。自动化模块,考虑现有的加工工艺中潜在的自动化改善点,制定合理的自动化方案。 细致规划阶段是在布局蓝图确定后,对各个模块的细化布局。侧重于细节的定义和优化,如生产物料、设备、桌椅的方向及位置,物流车的路线及站点。 完美的工厂精益布局,落地实施后即满足未来工厂业务扩张的需求,又提供完善的精益改善计划,为公司的健康稳定发展提供了强有力的支撑。
Read more
非生产领域的精益领导力
精益企业转型离不开精益领导力 精益领导力是我们在实施精益方法和工具的过程中,经常会忽视的一个重要元素。企业在精益转型的过程中,初期阶段可能是在某个或某几个特定的区域进行精益实施,例如5S,可视化,价值流;在经过一段时间之后,企业可能扩大了精益的应用范围和领域,并且形成了自己的精益管理体系。我们发现,初始阶段精益方法应用都取得了一定的成效,对企业管理绩效的提升起到了很强的促进作用,然而,在经过一定时间之后,对企业的可持续发展以促进达成卓越绩效的作用呈下降的趋势,其中被忽略的一个重要因素就是精益领导力。 什么是精益领导力 区别于传统的管理任务,精益领导力更多体现在管理现场,领导力实施的工具、原则、方式都与传统管理有很大的区别。精益领导力体现在管理者和员工的直接互动中。精益领导力通过完成以下任务得以发展: 持续的定期现场沟通 流程确认 结构化的问题解决 推动持续改善 培养员工 精益领导力不只是可视化管理和定期沟通 精益领导力任务 持续的定期现场沟通:各层级间清晰、一致的沟通,保持各层级完全了解企业和区域的最新状况,有效和高效的会议 。会议沟通均需尽可能高效,高效的会议管理应:直切要点 ,合理控制时间, 确定优先问题和行动 ,同时批准对策和行动,另外,所有与会者必须做好与会准备。 流程确认:确保现场有符合标准和最新的工作流程及规章制度,保证员工和管理者对流程规章制度的理解是一致的,如果标准没有被遵守,从现场发现不被遵守的原因,并识别标准是否有改善的的潜力。通过流程确认可以了解标准在企业的执行情况从而促进标准执行力的提升。 结构化的问题解决:识别和消除根本原因,达成可持续的问题解决方案。作为问题解决流程的一部分,领导者将问题解决与员工的进一步发展联系起来。在领导者以导师角色与员工互动并解决问题的过程中,员工接受指导,并提升了其分析和工作能力。同时,这种符合问题解决流程的方式有利于达成可持续的问题解决方案,同时也可以帮助领导者提高个人能力。 推动持续改善:领导者鼓励改进方法,并在企业内部通过现场管理的形式将推动持续改进的变革能量传送到各个管理层,从而真正的实现全员改善,打造企业的持续改进文化。 培养员工:为了使员工获得进一步的发展,领导者应营造良好的氛围,使员工能感受到有人倾听他们的想法和问题,有自己解决问题的氛围。领导者应针对个人设定不同情境下的挑战,便于员工进行观察学习,使他们在解决问题时能获得支持。 精益领导力的应用 精益领导力的实施通过现场管理在各层级的导入得以实现。可以在以垂直管理的模式下进行,不仅可以使部门/团队日常工作和绩效指标可视化 ,也能通过对组织单元的具体任务的计划和完成状态进行微观跟踪,将最低职级的部门信息关联至企业最高层级并对重要信息的偏差加以预警。 也可以以价值流形式的组织进行实施。价值流导向,跨部门可视化展示,展现流程任务和跨职能活动的状态,为不同职能团队提供任务优先级排定(如有任务冲突),流程整体状态回顾。 或者以项目(单个或多个)形式的组织进行实施:能够使项目信息和状态可视化,项目现场管理作为项目信息定期沟通的形式给不同项目组成员提供交流合作的机会,追踪项目任务活动的状态并为项目的重要节点和任务提供预警机制,呈现项目的总体状态等。 精益领导力实施促进企业对员工的培养,加快企业精益文化的形成,加速企业的精益转型,是企业可持续发展不可忽略的一部分。
Read more